The UA/SA Sampling Algorithm used by DesignBuilder requires a number of options to be set to control the way that the input variables are sampled. These and other settings are made on the General Tab of the Calculation Options dialog.
Enter a description for the calculation. This text will be used to identify the results on the graph and any other related outputs.
The Start date set up for the base simulation on the analysis screen is displayed but cannot be edited here.
The End date set up for the base simulation on the analysis screen is displayed but cannot be edited here.
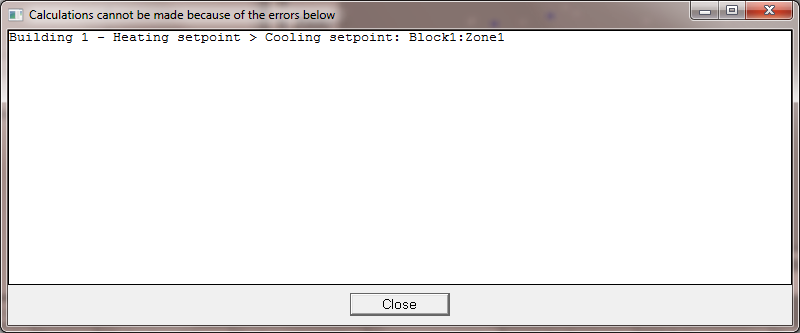
It is important to understand the cause of any errors that occur during an analysis. The Pause on errors option, when checked, causes a message to be displayed and the analysis is paused. For example, if there is an overlap in heating and cooling setpoint temperatures, in configurations where the heating setpoint is higher than the cooling setpoint the following error message is displayed:
This sort of error does not cause a problem for the overall Uncertainty and Sensitivity Analysis study. When calculating Uncertainty and Sensitivity analysis results these erroneous simulations are removed from the calculations.
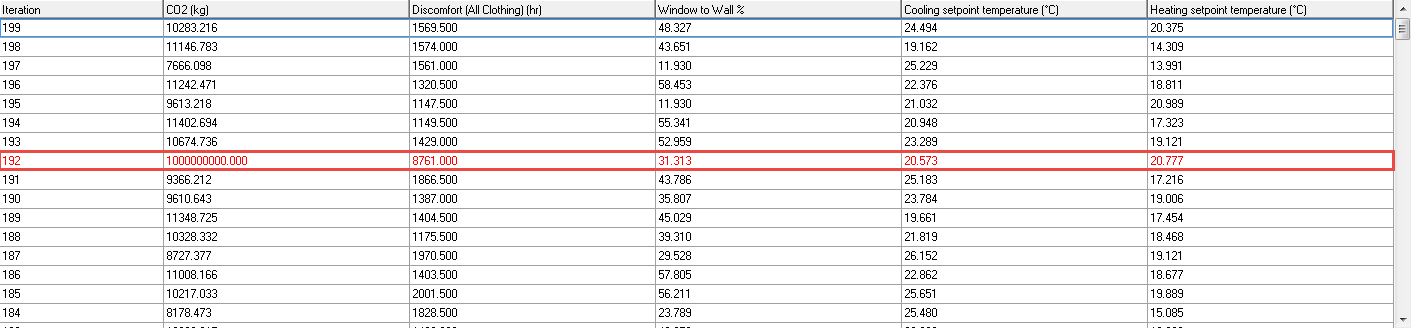
Once you are clear about the cause of any errors you will normally want to stop seeing reports and allow the optimisation to continue. To do this simply uncheck the Pause on errors check box. Simulations with errors are displayed in red in the grid as shown below.
Common causes of errors are:
Tip: Truncation can be used to limit such instances by removing the overlapping tails of the conflicting distributions’ inputs.
Normally, if DesignBuilder is unable to access the requested Simulation Server, it will ask you whether you would like to Abort, Retry or Ignore the missing server. Selecting Abort cancels the whole analysis. Selecting Retry or Ignore instructs the software to keep trying. The latter option would be selected if the server became temporarily unavailable, perhaps due to a network error or because the server was down for a while.
However, if you are running a long analysis and you don't want to be prompted in this way due to a temporary glitch in the availability of your simulation server then you can check this option. This is similar to pre-selecting the retry or ignore options in advance.
DesignBuilder supports Uncertainty and Sensitivity Analysis through implementing various sampling methods. DesignBuilder supports five sampling methods:
The Sensitivity Analysis method implemented in DesignBuilder is Regression.
Only required for the Random Walk sampling method. The value is multiplied with total variables to generate the total runs.
Runs =Trajectories * (Variables +1)
The recommended value for Number of trajectories is 20 if there are 10 or less number of design variables. For more than 10 variables this can be reduced in order to meet the computational demands.
This is the total simulations that are required. The number of runs to be used will determine the time and computing resources required to complete the analysis. The value entered here will usually reflect the size and complexity of the analysis. Typical values are in the range 50-500 depending on size of the problem, number of design variables and the population size.
The two most important factors to consider while selecting the value here are the Sampling option and the number of design variables. The table below can be used to select the minimum number of runs.
| Sampling Option | Number of Runs - Rule of thumb |
| Random |
20 times the number of variables |
| Random Walk | Not used. Define number of trajectories instead. |
| LHS |
10 times the number of variables |
| Sobol |
15 times the number of variables |
| Halton |
15 times the number of variables |
For cases where any of the design variables are discrete and have more than 10 options, then a higher value should be used to ensure that all options are simulated.
Tip: It is important to set number of runs correctly from the outset if a sensitivity analysis is required. In cases when a run is terminated, the sensitivity analysis results will not be shown and uncertainty analysis results may be incomplete. If sensitivity analysis results are not required then you can simply terminate the calculations once you are happy that the distribution curve displayed on the Calculation Options dialog during the analysis is sufficiently well developed and smooth.
The value here sets the maximum number of runs that are run in one set and gets plotted on the graph before the next set beings. Default value of results of simulations are plotted in batches is 20.
Note: All simulations for a set must complete before the next set is started so if you have many parallel cores at your disposal and the time taken to run the simulations is the main bottleneck in calculations (as opposed to IDF generation) then a higher number here can be helpful.
Normally results for each simulation are held within the Simulation Manager system only for as long as required and are deleted once the key results have been loaded into DesignBuilder. However, if you require results for each simulation to be retained within the Simulation Manager system then check this checkbox.
An important and often overlooked consideration is the impact of the time taken by DesignBuilder to generate the IDF input file for each design. The longer this is relative to simulation time the greater the model generation bottleneck and the less useful the large number of parallel simulations. On the other hand, the larger and more complex the model and the more detailed the simulations (nat vent, detailed HVAC, more time steps etc) the more time is taken in simulation and relatively less in IDF generation. For an extremely large/complex model, all IDF inputs will have been generated before the first results are in and the large number of parallel simulations will speed progress. For a smaller model, the IDF generation bottleneck is more significant and first simulation results will be in before the 3rd or 4th IDF input has been generated and, in this case, the multiple cores will not be needed. This is often the case for simple single zone models. To test and understand this watch the Simulation Manager while the optimisation takes place. You will see new jobs being submitted, queued and simulated.